Running LLMs Locally with Ollama
Testing which LLMs my NVIDIA GeForce RTX 4060 Ti can run locally.
This blog post belongs to a two-part series: Ollama Local LLMs
- Running LLMs Locally with Ollama (this page)
- Building Something with Local LLMs
Is there any value in running small LLMs locally when all the big tech companies offer free credits for truly large LLMs? Will my graphics card explode under my desk?
Running Our First Ollama Inference
I have the following system specs, displayed courtesy of screenfetch.

The key takeaway is that I have 16 GB of VRAM available in my GPU, so I’m limited to models that around that size. (It turns out, the sweet spot for model size ends up being about half my available GPU VRAM. This is because inference on large context eats up the remaining VRAM.)
To begin, I simply Google’d “run llms locally” and chose to follow this useful guide from Jeremy Morgan. Here are the two commands I needed to get up and running. Beware of piping commands into sh.
alexshank@alex-desktop:~/Desktop/main/repos/blog-astro$ curl -fsSL https://ollama.com/install.sh | sh
>>> Installing ollama to /usr/local
[sudo] password for alexshank:
>>> Downloading Linux amd64 bundle
######################################################################## 100.0%
>>> Creating ollama user...
>>> Adding ollama user to render group...
>>> Adding ollama user to video group...
>>> Adding current user to ollama group...
>>> Creating ollama systemd service...
>>> Enabling and starting ollama service...
Created symlink /etc/systemd/system/default.target.wants/ollama.service → /etc/systemd/system/ollama.service.
>>> NVIDIA GPU installed.
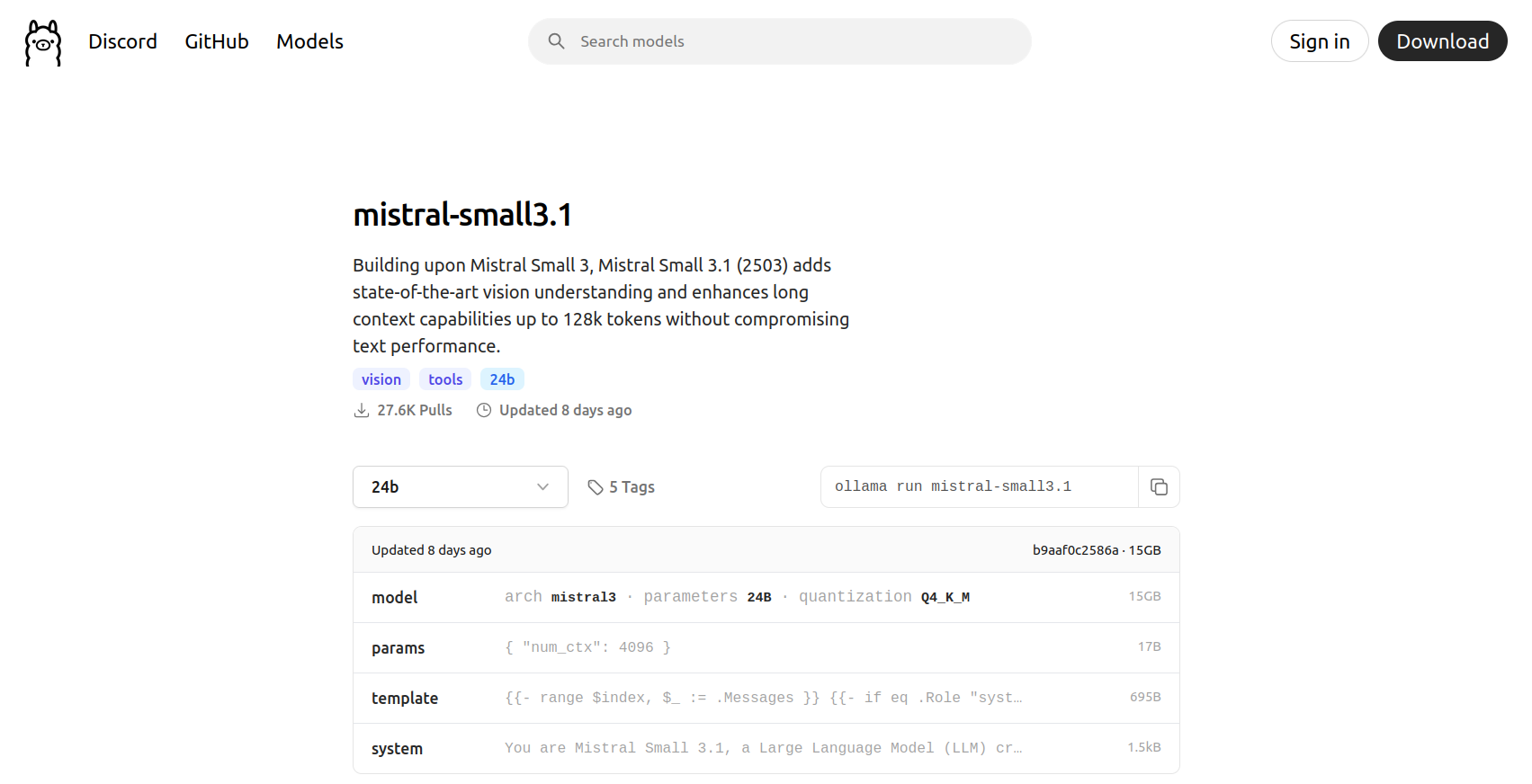
alexshank@alex-desktop:~/Desktop/main/repos/blog-astro$ ollama run mistral-small3.1
pulling manifest
pulling 1fa8532d986d... 100% ▕████████████████████████████████▏ 15 GB
pulling 6db27cd4e277... 100% ▕████████████████████████████████▏ 695 B
pulling 70a4dab5e1d1... 100% ▕████████████████████████████████▏ 1.5 KB
pulling a00920c28dfd... 100% ▕████████████████████████████████▏ 17 B
pulling 9b6ac0d4e97e... 100% ▕████████████████████████████████▏ 494 B
verifying sha256 digest
writing manifest
success
>>> hello
Hello! How can I assist you today?
> > > What's the capital of italy?
> > > The capital of Italy is Rome.
Browsing Available Models
Before I ran the above prompt, I looked at the most popular models on the Ollama site and chose mistral-small3.1. There’s a good amount of buzz around Mistral, and it even has some vision capabilities.
I’m not overly concerned with the quality of individual models we’re demoing here. I’m primarily interested in exploring the capabilties and features of the models, along with Ollama’s integrations. Let’s explore the following capabilities using selected models I did very brief research on:
- Audio -> Text Generation (Audio Transcription)
- Multi-Modal Embeddings (for RAG and Vector DBs)
- Integrations (e.g., Ollama server API, Model Context Protocol, Claude Code drop-in, etc.)
Let’s see if we can do anything interesting in these areas. Quickly browsing Ollama, I’ve landed on these models.
| Model Name | Parameters | Capabilities |
|---|---|---|
mistral-small3.1 | 24 billion | Text + Image -> Text Generation |
deepseek-ocr:3b | 3 billion | Text + Image -> Text Generation (OCR) |
x/flux2-klein:4b | 4 billion | Text -> Image Generation (No Linux support yet from Ollama 🙁) |
gemma3n:e4b | 4 billion (effective) | Text + Image + Audio -> Text Generation (No audio input support yet from Ollama 🙁) |
nomic-embed-text-v2-moe:latest | 305 million | Text Embeddings |
MedAIBase/Qwen3-VL-Embedding:2b | 2 billion | Multi-Modal Embeddings (Throwing an inscrutable error for me 🙁) |
Image generation and audio input aren’t fully supported in Ollama yet, even though the underlying models can be downloaded. We’ll explore Whisper and Stable Diffusion Web UI to fill in the gaps.
Text Generation
TODO.
Ensuring We’re On the GPU
TODO.
Tokens Per Second
TODO.
Whisper
TODO.
Stable Diffusion Web UI
TODO.
Vector DBs and RAG
TODO.